Introduction¶
Welcome to the Gencove Explorer analysis cloud docs!
For Gencove Base documentation, see here.
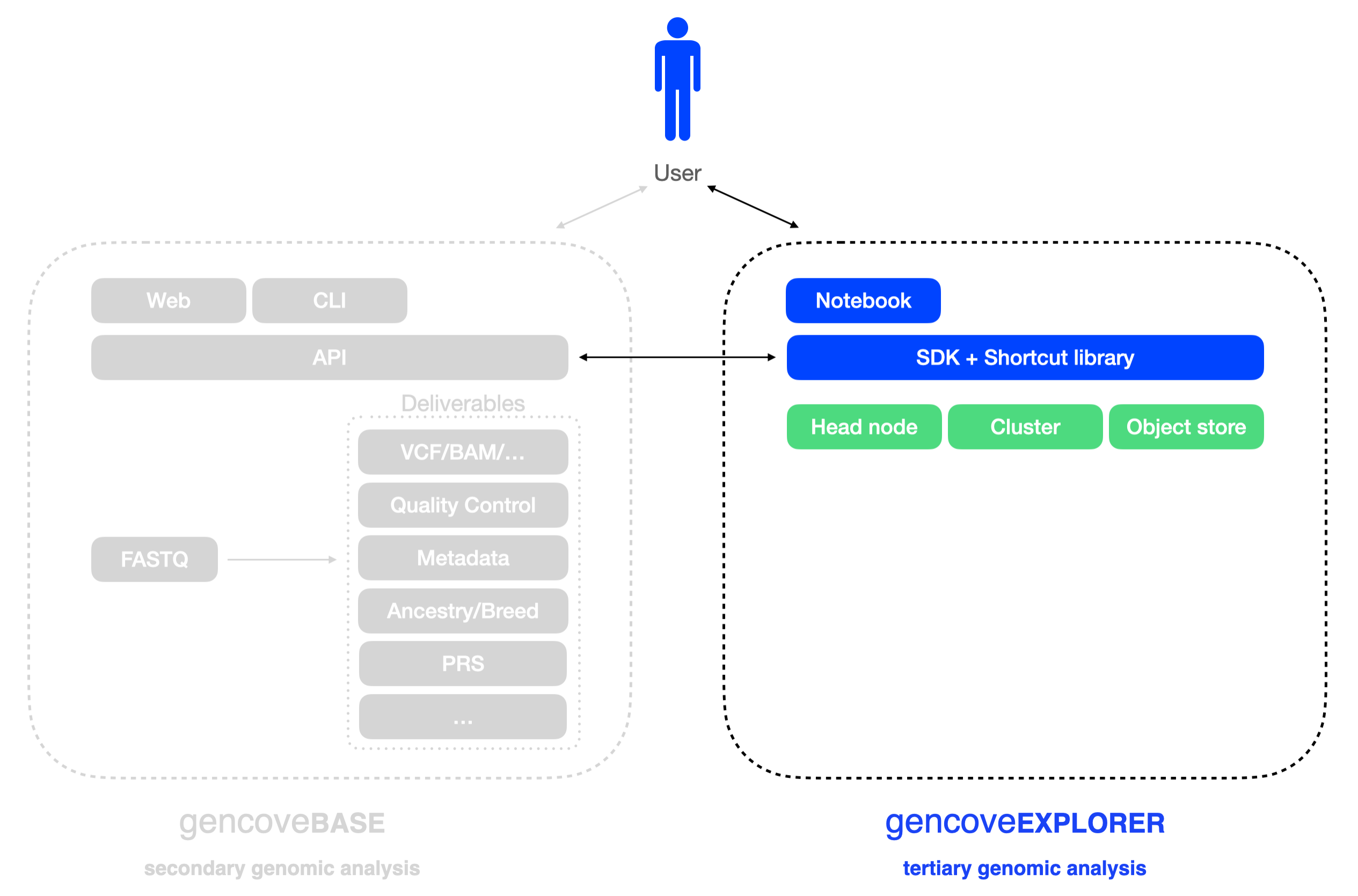
Gencove Explorer is a cloud-based data analysis platform for easily processing and querying genomic data. It enables data scientists and researchers to focus on answering biological questions by abstracting away the need for managing scalable computational infrastructure or reinventing the wheel for known bioinformatics workflows.
Although built with special consideration for genomics applications and Gencove datasets in mind, Explorer is a general-purpose computing platform on which general scientific computing can be easily performed.
At a high level, Explorer comprises the following systems:
- An Explorer instance (an EC2 instance), which is a Linux machine with which you interact through a hosted JupyterLab instance
- A scalable compute cluster (implemented using AWS Batch), to which you can submit arbitrary analysis jobs
- A private docker image repository, for publishing custom images used by the compute cluster
- A persistent object store (hosted on AWS S3), on which you can store your data and outputs of analyses
- The Explorer SDK, a lightweight Python module which makes it easy to interface with both the compute cluster and object storage and which additionally provides helper functions to work with Gencove data
For those with a more traditional cluster computing background, one can think of the Explorer instance as the head node of a cluster, on which light analyses can be performed and from which jobs that require heavy lifting can be submitted to the Batch cluster through use of the Explorer SDK. The difference here is that persistent object storage is achieved through the use of AWS S3 rather than, for example, a shared filesystem on the compute nodes of the cluster.
A variety of abstractions for cluster jobs and input/output files are implemented in the Explorer SDK.
Particularly of note is an abstraction of an "analysis" (implemented through a Python Analysis object), which encapsulates a "work function" (i.e., what is to be executed, and on what, and what is the expected output) associated with a job that is submitted to the Explorer cluster, which enables the straightforward definition of the inputs, outputs, and other parameters, as well as the subsequent retrieval of output files generated by these jobs.
Furthermore, the SDK enables the definition of dependencies between multiple different analysis jobs, such that entire workflows with various sequential and interdependent steps can easily be defined and executed on the Explorer-provided cluster (without having to manage the underlying infrastructure) as long as the workflow can be represented as a directed acyclic graph (DAG).
Use Cases¶
Gencove Explorer and the Explorer SDK come with native functionality to enable convenient exploration and analysis of Gencove-generated data, but the cluster infrastructure and job-based analysis framework is built for general-purpose scientific computing.
Launching Explorer¶
Gencove Explorer can be accessed by logging into the Gencove platform and clicking the Explorer button:
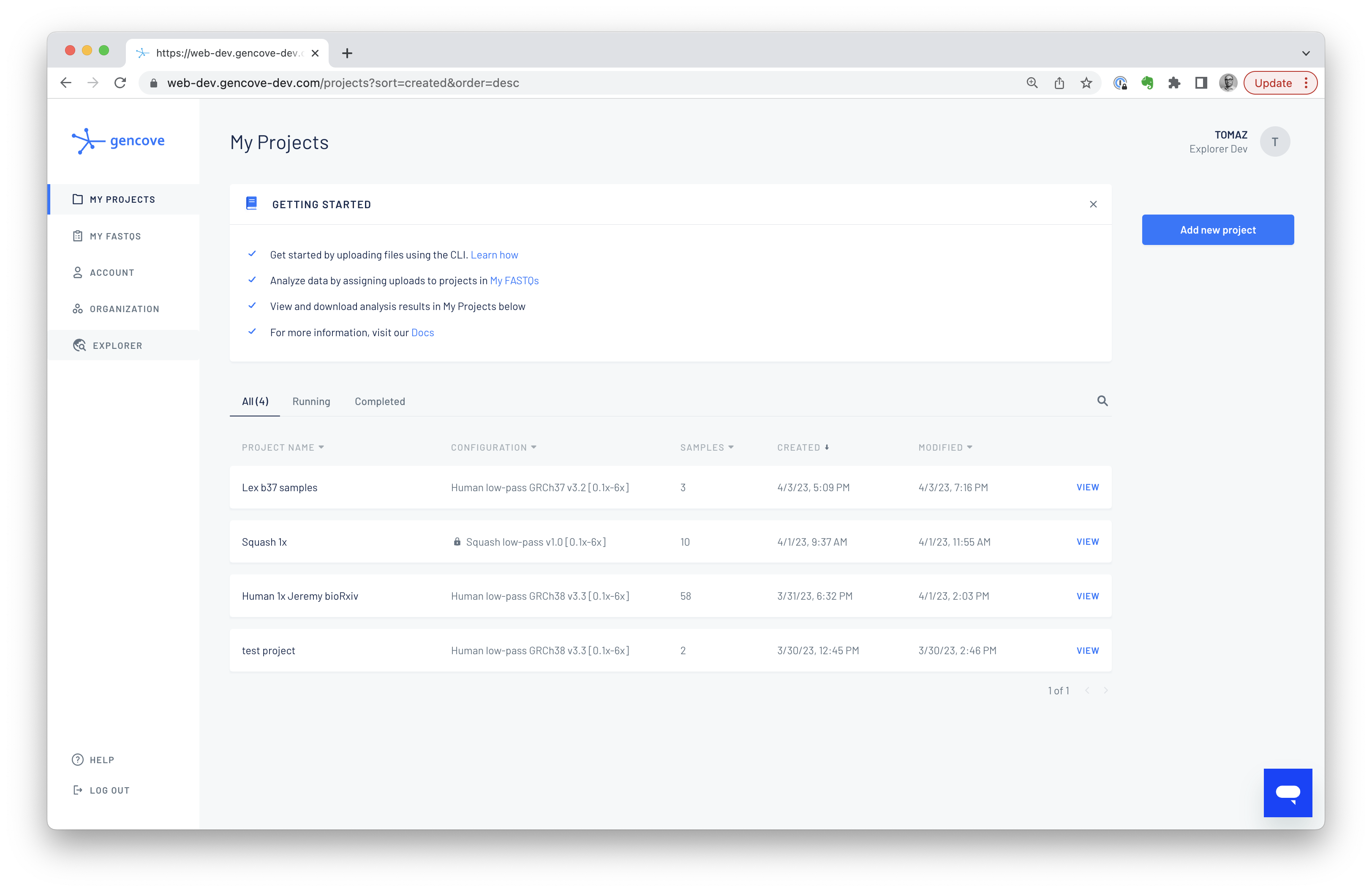
which will open a new tab and drop you into JupyterLab on your Explorer instance:
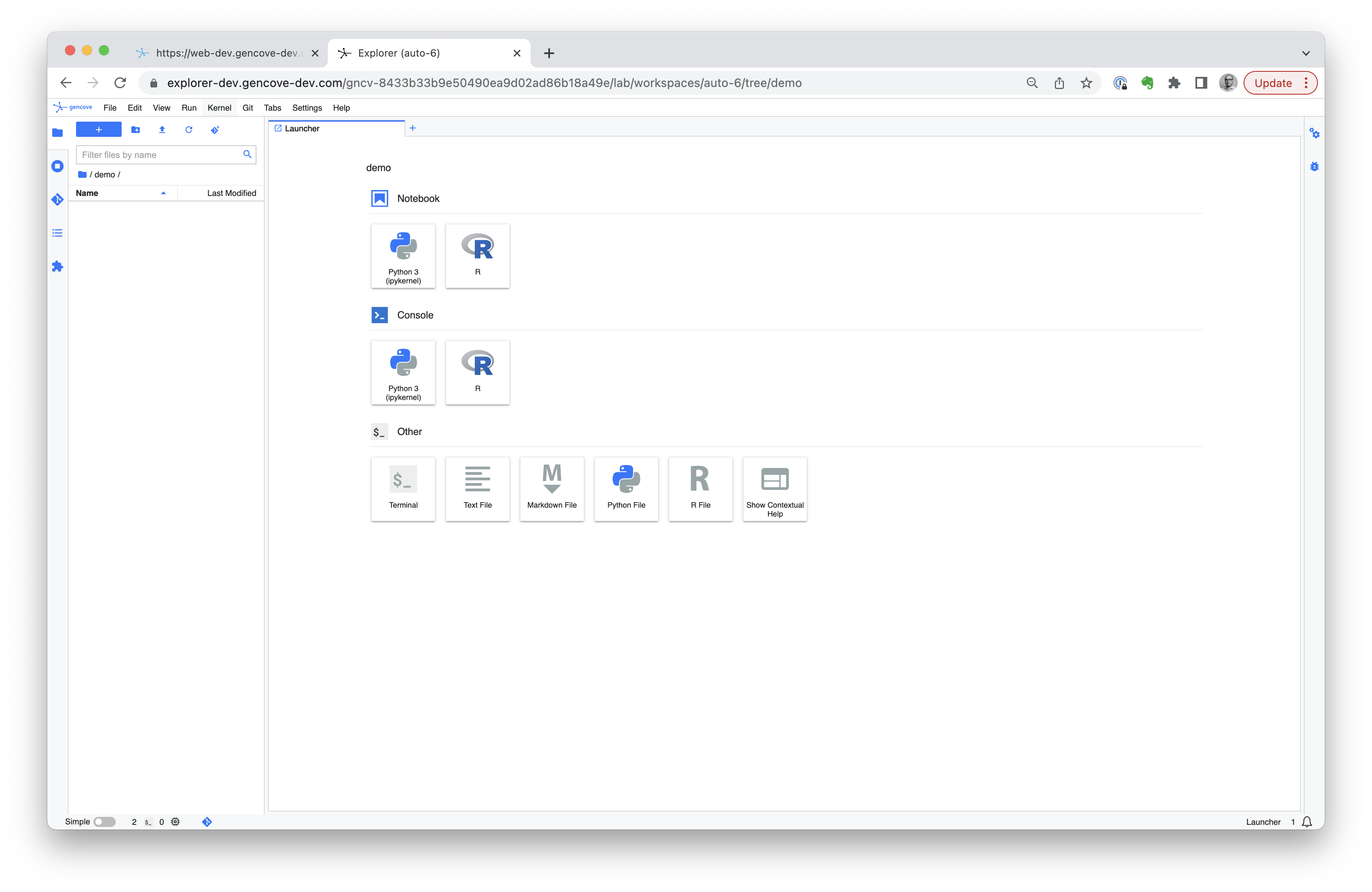
A couple notes:
- In some cases, you may experience a brief delay lasting 2-3 minutes when accessing Explorer for the first time. This is normal.
- The notebook session lasts for 12 hours, after which the notebook needs to be opened again. The notebook server itself is not restarted, so any work will be autosaved and available upon reopening the notebook.
Quickstart and running your first cluster job¶
To quickly get started, open a new Python 3 notebook and try out the examples below. Note that your Explorer instance is at its core a standard Linux machine (based on Ubuntu 22.04), so you can interact with it through the shell as you normally would with any other Linux environment.
The Explorer SDK comes preinstalled on your Explorer instance, and can be accessed through a simple import gencove_explorer statement.
A small Hello World "analysis" example¶
In this minimal example, we will define an analysis job that simply prints "Hello World," and walk through how you would run this job locally as well as how you would submit it to the Explorer cluster.
We specifically avoid going into the details regarding the syntax and details of what each step does, as this information is provided in SDK Reference documentation.
The following code snippet defines the function work()
from gencove_explorer.analysis import Analysis, AnalysisContext
# define the analysis job
def work(ac: AnalysisContext):
print("Hello World")
# initialize an analysis object
an = Analysis(
function=work
)
which we can then proceed to test run locally; i.e., on the Explorer instance that is running the Jupyter notebook.
# run the job locally in a virtual environment that we name `my-test-virtualenv`
an.run_local(env_name="my-test-virtualenv")
💡 Note that the first run takes a few minutes to initialize the Python virtual environment and install all required packages.
💡 Although env_name is an optional parameter for run_local(), it is highly recommended to use it in order to create a reusable Python virtual environment for quick local iteration. Otherwise, Explorer will create a new temporary virtual environment (and install all required packages) on every execution, which takes a long time.
The run_local() method can be executed as many times as needed for development and testing throughout the lifetime of the Analysis object. Its output is printed to stdout and stderr, both of which are available in real-time in the notebook cell output.
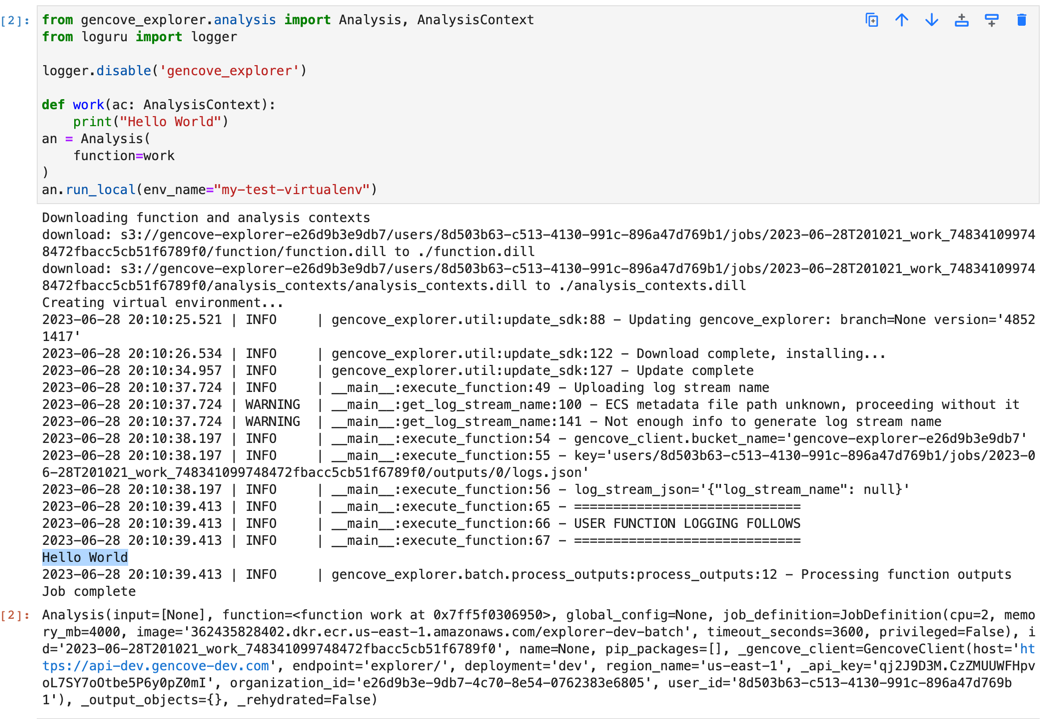
In the screenshot above, you can see the output of executing this code.
Submitting the analysis job to the Explorer cluster¶
That same work() function can be run remotely on the cluster with the run() method.
After submission, the status of the job execution can then be queried using the status() method of the analysis object and standard output and error can be fetched using the logs() method.
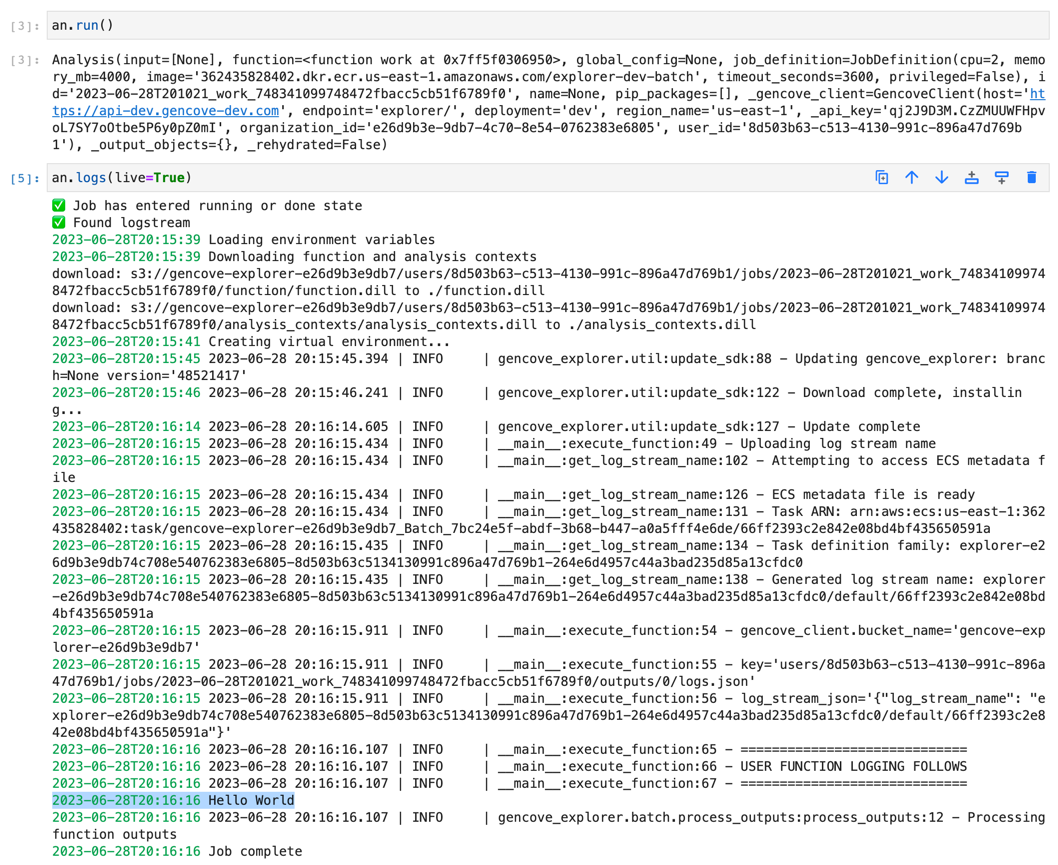
The screenshot above illustrates what you would see after submitting this to the cluster, as well as the logs retrieved directly from the cluster nodes.
The logs() method accepts two parameters:
liveprovides a live tail of logs until the job completessinceindicates how long into the past to display logs (default:10m, i.e., 10 minutes)- Note that this parameter needs to be adjusted to a higher value when requesting logs for a job that completed longer than 10 minutes ago.